OpenAI王炸第二弹强化微调:12个例子搞定专业学习推理,Altman称为今年最大惊喜
- 体育
- 2024-12-07 08:32:05
- 45
专题:OpenAI开启12天狂欢
来源:华尔街见闻
OpenAI研究员演示,强化微调后的o1 mini测试通过率甚至比正式版o1高24%,比未强化微调的o1 mini提高了82%。
OpenAI连续12天“王炸”的第二弹来了。不同于第一日聚焦人工智能(AI)模型,第二日的王炸专注于服务企业等组织的一款新功能,虽然看起来不太侧重于普通消费者,但据介绍它甚至可以简易版推理模型o1 mini的效果超过本周四发布的正式版o1、即所谓满血o1。
美东时间12月6日周五,OpenAI在社交媒体X公布第二日活动的主题是新功能“强化微调”(Reinforcement Fine-Tuning)。这个主题是指,企业组织将能够通过“强化微调”微调o1 mini,满足他们的特定需求。
OpenAI CEO Sam Altman在X发帖称,强化微调的效果非常棒,是他今年最大的惊喜之一,期待看到大家利用这种功能的创造。
OpenAI的研究员本周五介绍,科学家、开发人员和研究人员可以根据自己的数据、而不是仅仅使用公开可用的数据,量身定制OpenAI的强大推理模型o1。不同行业的人可以使用强化学习来创建基于 o1 的专家模型,从而提高该领域的整体专业知识水平。开发者、研究者和机器学习工程师将首次能运用强化学习,打造在精通他们各自专业领域的专家模型。
OpenAI的研究员称,强化微调并不是单单教模型模型输出,它的运作方式是,当模型发现一个问题的时候,研究者给模型空间区仔细思考这个问题,然后评估模型给出的最终解答,运用强化学习,研究者可以强化产生正确答案的思路,抑制产生错误答案的思路,只需要“几十个例子”(a few dozen examples)、甚至12个例子,模型就能以有效的新方式学习特定领域的推理。
通过强化学习,用户可以用大模型在特定数据上训练其他模型。这对于涉及到大量数据的复杂领域或需要专家领域知识的新研究非常有用。研究者举例称,最近和汤森路透合作,运用强化微调微调o1 mini,让充当法务助理,帮助他们的法律专业人士完成大部分分析工作流。
OpenAI称,OpenAI的定制模型平台将支持强化学习,强化学习也是OpenAI内部用于训练自家前沿模型的技术,如GPT-4o和o1系列模型。在OpenAi的内测中,强化微调已经在生物化学、安全、法律和医疗保健领域取得成功。OpenAI计划,2025年初让强化微调面向公众发布,目前已对企业、大学和研究院开放申请测试通道。
伯克利大学罕见遗传病研究员 Justin Reese参与了OpenAI本周五对o1 mini模型的现场演示。演示中,研究者试图从样本数据池中获取可能导致疾病的模型 ID 基因。
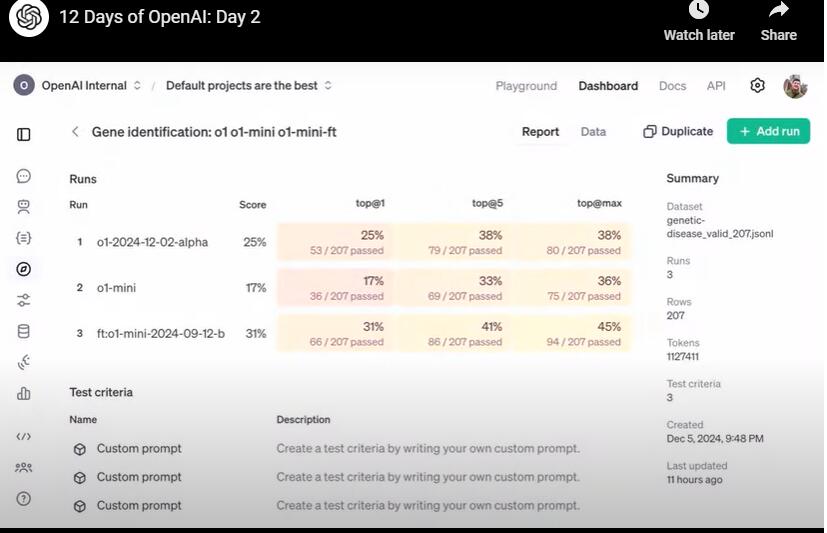
研究员展示了一个评估表,下图可见,第一行是本周四OpenAI发布的正式版o1测评表现,第二行是o1 mini的测评结果 ,第三行结果来自经过最终强化微调的o1 mini。研究员进行了三类评估,其中,top @1是测试模型给出的正确答案出现在列表最前列中的概率,top@5是正确答案出现在前五列的概率,top@max是答案出现在所有正确答案列表的概率。
如图所示,正式版o1的测试通过率为25%,o1 mini为17%,而强化微调后的o1 mini竟然达到31%,超过了正式版o1,比正式版o1的测评结果高24%,而且相比未强化微调前,微调后的结果提高了82.3%。
据OpenAI所说,用户可以综合运用o1、微调和数据创建定制的小型 o1模型 o1 mini。用户要做的就是提供数据,然后在强化微调方面,设置一个数据集和一个“评分器”,根据训练和验证数据集评估模型的性能,其他工作交给OpenAI。
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。
发表评论